Recentemente assisti a um vídeo muito bom do canal ByteMonk chamado “Embeddings, Vector database, Agent, RAG & MCP: How Modern AI Systems Actually Work” (link aqui) e resolvi trazer um resumo dos conceitos abordados, porque são peças fundamentais para entender como os sistemas de IA modernos funcionam na prática.
Embeddings: como a IA entende significado
Embeddings são representações numéricas (vetores) que capturam o significado semântico de palavras, frases ou documentos. Em vez de tratar texto como simples sequências de caracteres, os modelos de IA transformam o conteúdo em listas de números onde conceitos similares ficam próximos no espaço vetorial.
Na prática, isso significa que uma busca por “aumentar receita” pode encontrar documentos sobre “crescimento de vendas”, mesmo sem ter palavras em comum. É isso que permite a busca semântica — ir além do match exato de palavras-chave.
Vector Databases: onde os vetores moram
Se embeddings são os vetores, as Vector Databases são os sistemas de armazenamento otimizados para buscas por similaridade. Diferente de bancos de dados tradicionais que fazem buscas exatas, um vector database encontra os “vizinhos mais próximos” entre milhões de vetores em milissegundos.
Exemplos populares: Pinecone, Weaviate, Chroma, Qdrant e pgvector (extensão do PostgreSQL).
O caso de uso clássico é armazenar chunks de documentos como vetores pesquisáveis, servindo de base para sistemas de RAG.
RAG (Retrieval-Augmented Generation): dando contexto ao LLM
RAG é a técnica que conecta tudo isso. O fluxo é elegante:
- O usuário faz uma pergunta
- A pergunta é convertida em um embedding
- O sistema busca documentos relevantes no vector database
- Esse contexto é injetado no prompt do LLM
- O modelo gera uma resposta baseada tanto no seu treinamento quanto nas informações recuperadas
O grande benefício do RAG é que o LLM consegue responder com informações atualizadas e específicas do seu domínio, sem precisar ser retreinado. Isso resolve um dos maiores problemas dos modelos de linguagem: o conhecimento limitado à data de corte do treinamento.
MCP (Model Context Protocol): padronizando o acesso a dados
O MCP (Model Context Protocol) é um protocolo que padroniza como aplicações de IA acessam fontes de dados externas. Em vez de cada integração precisar de código customizado, o MCP oferece interfaces padronizadas para que agentes de IA se conectem a bancos de dados, APIs e ferramentas de forma segura e consistente.
Enquanto o RAG foca em recuperar informações não-estruturadas para enriquecer prompts, o MCP trata o contexto como entradas dinâmicas, estruturadas e compostas, passadas via um protocolo formal. Na prática, RAG e MCP são complementares: o RAG busca o conhecimento relevante e o MCP padroniza como esse conhecimento (e outras ferramentas) chegam até o modelo.
Mão na massa: exemplos de código
Gerando um embedding com a API da OpenAI:
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
model="text-embedding-3-small",
input="Como funcionam os sistemas modernos de IA?"
)
vetor = response.data[0].embedding
print(f"Dimensões do vetor: {len(vetor)}")
# Dimensões do vetor: 1536
Fazendo uma busca por similaridade com ChromaDB:
import chromadb
client = chromadb.Client()
collection = client.create_collection("meus_docs")
# Inserindo documentos (o Chroma gera os embeddings automaticamente)
collection.add(
documents=["RAG conecta LLMs a bases de conhecimento",
"Docker isola aplicações em containers",
"Embeddings capturam significado semântico"],
ids=["doc1", "doc2", "doc3"]
)
# Buscando por similaridade
resultados = collection.query(
query_texts=["como dar contexto para uma IA?"],
n_results=2
)
print(resultados["documents"])
# [['RAG conecta LLMs a bases de conhecimento',
# 'Embeddings capturam significado semântico']]
Note que a busca retornou os documentos semanticamente relevantes, mesmo sem palavras em comum com a query.
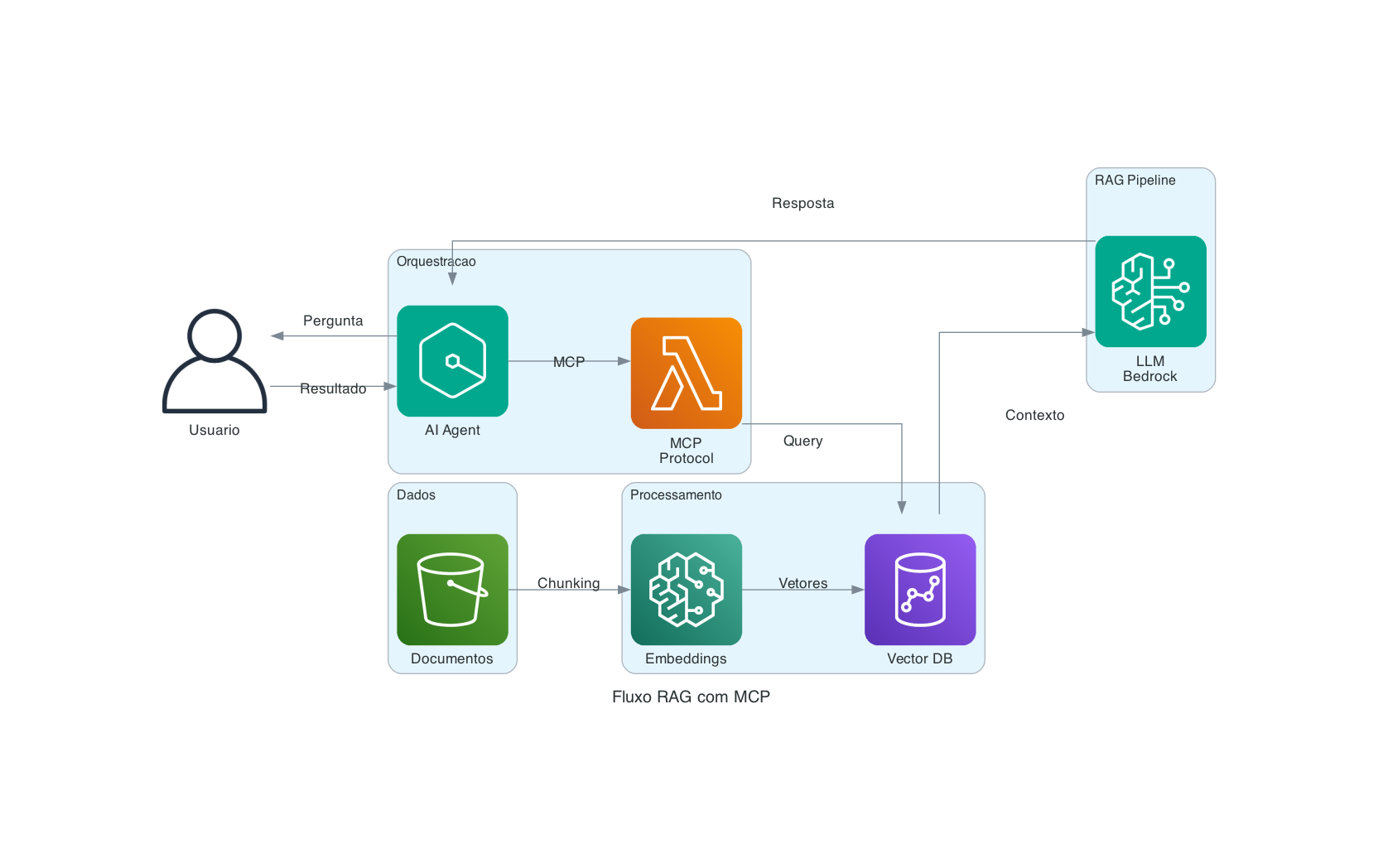
Como tudo se conecta
┌──────────┐ ┌──────────────┐ ┌───────────┐ ┌─────────┐ ┌──────────┐
│ │ │ │ │ │ │ │ │ │
│ Dados ├───►│ Embeddings ├───►│ Vector DB ├───►│ RAG ├───►│ LLM │
│ │ │ │ │ │ │ │ │ │
└──────────┘ └──────────────┘ └───────────┘ └────┬────┘ └─────┬────┘
│ │
┌────▼────┐ │
│ │ │
│ MCP ◄─────────┘
│ │
└────┬────┘
│
┌─────▼──────┐
│ │
│ AI Agent │
│ │
└────────────┘
Resumindo a stack:
- Embeddings transformam dados em vetores com significado semântico
- Vector Databases armazenam e buscam esses vetores de forma eficiente
- RAG usa essa infraestrutura para dar contexto relevante ao LLM em tempo de consulta
- MCP padroniza a comunicação entre o agente de IA e todas essas fontes de dados e ferramentas
- AI Agents orquestram tudo isso, planejando consultas em múltiplos passos e adaptando a estratégia conforme os resultados
Para ir além
- OpenAI Embeddings Guide — documentação oficial sobre embeddings
- ChromaDB — vector database open-source, ótimo para começar
- Pinecone Learning Center — tutoriais sobre vector databases e busca semântica
- LangChain RAG Tutorial — tutorial prático de RAG com Python
- Model Context Protocol (MCP) — especificação oficial do protocolo
- Vídeo original do ByteMonk — o vídeo que inspirou este post
Nos vemos por aí!